Innovation Model: Belt-Clip “Smart Hub”
Aurix is built exclusively for low-income communities. Our model reduces cost and stigma by moving expensive processing out of the ear and into a modular belt-clip hub.
How Aurix Works (3 Pillars)
Decentralized Design
Move the core hardware out of the ear canal into a belt-clip box—dramatically cutting the cost of precision miniaturization.
AI Adaptive Noise Reduction
Optimized for factories, traffic, and other loud settings—automatically enhancing speech while filtering harmful noise.
Dual-Mode Switching
One tap to switch between hearing-assist mode and Bluetooth earphone mode—work and life, seamlessly connected.
System Architecture (Simplified)
A clear path: capture → enhance speech → output, with a safe power chain.
Audio signal path
Power path
Prototype Gallery

Prototype showcase: Universal 3.5mm interface and tactile control knob for a frictionless user experience.

Internal layout: modular wiring and control board design for low-cost maintenance and upgrades.
Why this form factor matters
By shifting complexity into a belt-clip hub, Aurix reduces specialized miniaturization, improves repairability, and keeps the ear-side discreet—key for adoption in low-income communities where both cost and stigma are barriers.
Model Evidence: MFCC Comparison
Visualizing the difference between raw mixed audio and denoised output (environment + speech).
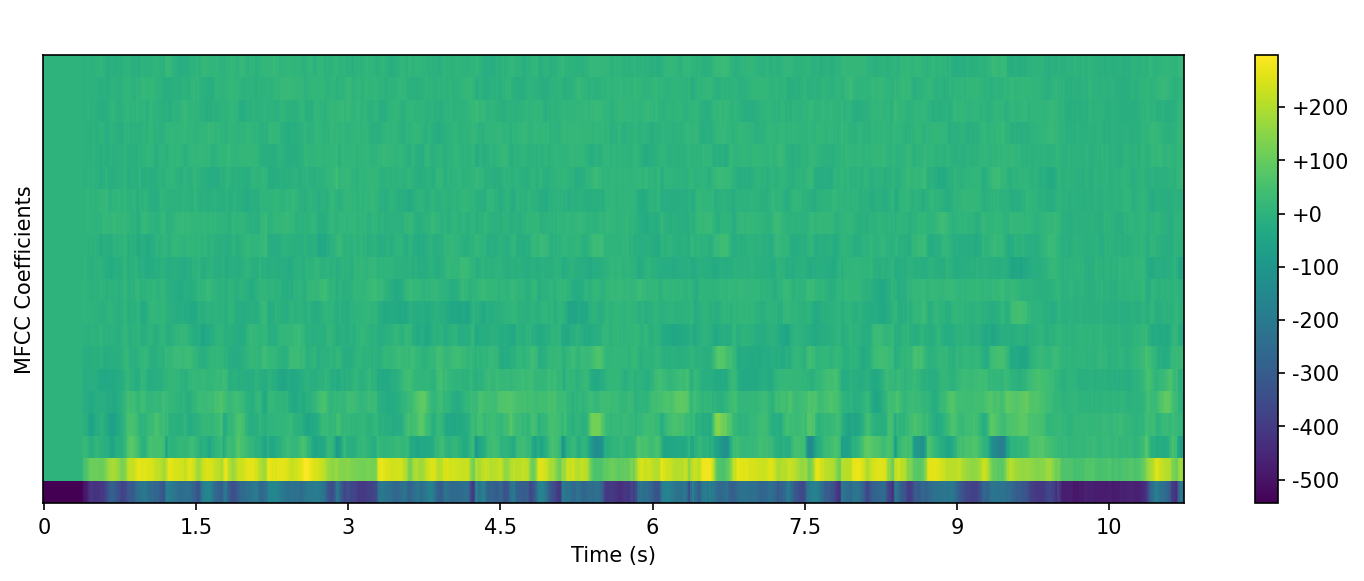
Denoised Output MFCC (Environment + Speech)
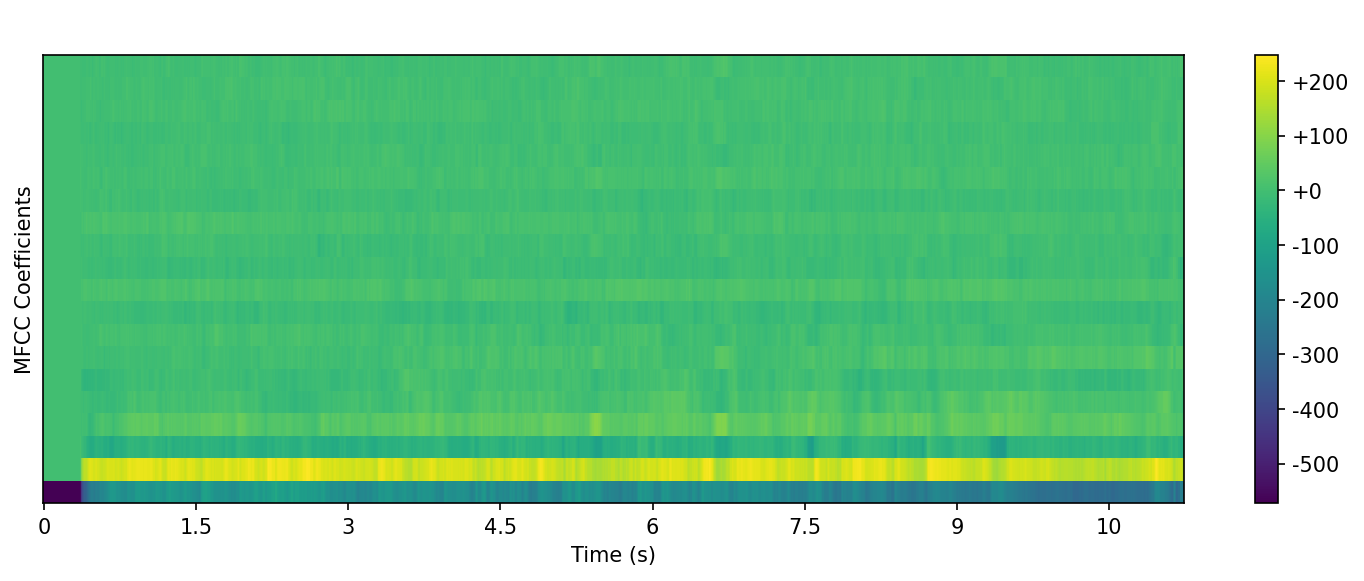
Raw Mixed Output MFCC (Environment + Speech)
What to look for
- • The denoised MFCC shows clearer structure that corresponds to speech features.
- • The raw mixed MFCC contains more scattered energy from background noise.
- • This supports our goal: speech-first listening in noisy working environments.